OMI-DB collects processed and unprocessed mammographic images. Unprocessed images are essential for certain research projects but are unfortunately discarded by most PACS systems used in the NHS. To overcome this, special arrangements have been made at some of the clinical sites from which images are collected to ensure that unprocessed images are kept. OMI-DB also collected very-high risk MRI images, Tomosynthesis assessment images and Symptomatic setting mammographic images.
The collection process is fully automated. Data managers (NHS employees) setup and manage the automated systems. Access to the system is restricted to these data managers only. No researchers have access to the research servers.
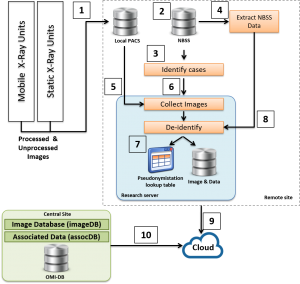
Overview of OMI-DB image collection protocol. You can click on the numbered tabs bellow to find out more details about each of the image collection steps.
Image Types
OMI-DB contains breast screening mammography images, Tomosynthesis assessment images, very-high risk MRI and symptomatic images.
Processed and Unprocessed Mammographic Images are stored on the site's local PACS
The need to collect unprocessed images is important for many research applications. Unprocessed images are essential for studies on different types of image processing and computer-aided detection. The pixel values and the noise in the unprocessed images also have a direct link back to the physics of the image formation. Once the images are processed this link is lost and cannot be recovered. Unprocessed images can also be used to study the effect of different design parameters on clinical performance. Unfortunately, most PACS systems used in the NHS store only processed images and the unprocessed images are discarded. As a result, special arrangements have been made at some of the clinical sites providing images for OPTIMAM to ensure that unprocessed images are not discarded.
Connection to National Breast Screening System (NBSS)
Connection to the NBSS is made between the OPTIMAM Research PC and the site’s NBSS database using an ODBC connection.
Identify Cases to be Collected
The automated collection system uses the NBSS connection to regularly query the NBSS database and identify cases to be collected. The selection criteria for malignant cases are based on newly occurring, closed screening episodes that result in a B5a or B5b biopsy status. The system also collects selected benign and normal cases. This process is automated and does not need any human intervention from the data managers.
Extract NBSS Data
The same NBSS connection is utilised by the automated collection system to extract information about the case from NBSS. The system collects de-identified information from the NBSS describing the diagnosis and screening history of the cases collected.
Dedicated On-Site Research Server
Each clinical site has a dedicated research server on which all the OPTIMAM tools reside. In order to monitor the status of the automated system, a remote connection is used to allow the data managers to access the systems. This access is restricted to only one IP address from the Royal Surrey County Hospital, and access is only possible by the data managers.
Extract Selected Images from PACS
Once a case has been identified, the next step is to extract copies of the images from the site’s PACS to the onsite research server. This connection is established between the sites PACS and a small implementation of a dcm4che (www.dcm4che.org) DICOM listener. In effect, this allows automated extraction of images from the sites PACS to the research server, based on input from the identification stage (step 3). The automation of this step has many benefits, including the ability to run the collection process overnight to avoid any burden on the PACS or local network.
De-Identification/Pseudonymisation Process
The newly collected images are then de-identified/pseudonymised and the pseudonym is saved in a local database residing on the research server. This database also stores the NHS number, the internal episode ID and Study UID of the cases. Details of the de-identified/pseudonymisation are given in the subsequent pages. The de-identified images are stored on the research server and the original copies of images and data are permanently deleted.
De-Identify Clinical Data from NBSS
The data from the NBSS is pseudonymised using the lookup database already populated in the previous step and is encoded in a JavaScript Object Notational format (JSON) format. These JSON formatted files are placed in the folder with the de-identified images.
Secure Upload to Cloud Storage
In order to centralise the cases we have collected, the pseudonymised images are uploaded to the cloud. Once confirmation is received that all images and data have been successfully transferred, all images and data are deleted from the research servers at the clinical sites. Our selected cloud provider is designed with multiple layers of protection, including secure data transfer, encryption, network configuration, and application-level controls distributed across a scalable, secure infrastructure.
Download to Central Database
The collected cases are downloaded from the cloud by the data managers when the researchers require access.